Ceph通过CRUSH放置算法,来计算哪些OSD应该保存哪些对象,对象是放到PG中,而CRUSH决定这些PG应该放在哪些OSD中,
CRUSH算法与对象放置策略
CRUSH算法
CRUSH算法使Ceph客户端可以直接与OSD通信:Ceph客户端与osd使用CRUSH算法来有效计算关于对象位置的信息,而不是依赖于中央查找表,避免了单点故障和性能瓶颈
作用:在对象存储中均匀分布数据、管理复制、响应系统增长和硬件故障
当新增OSD或已有OSD或OSD主机故障时,Ceph使用CRUSH来重新平衡集群中活动OSDs之间的对象。
CRUSH映射组件
一个CRUSH映射包含两个组件,整个集群只有一份CRUSH Map,不同pool可以使用不同Rule
CRUSH hierarchy层次结构
通常用于表示osd位置
列出了所有可用的osd,并将它们组织成树状的桶结构
默认情况下有一个根桶代表整个层次结构,下面每个主机对应一个主机桶
At least one CRUSH rule至少一个CRUSH规则
CRUSH规则决定了如何从这些桶中为PG分配osd,决定了PG的对象存储在哪里。不同的池可能使用不同的CRUSH规则


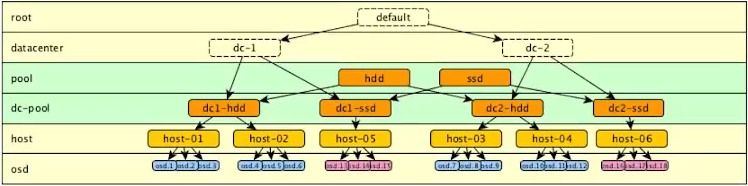
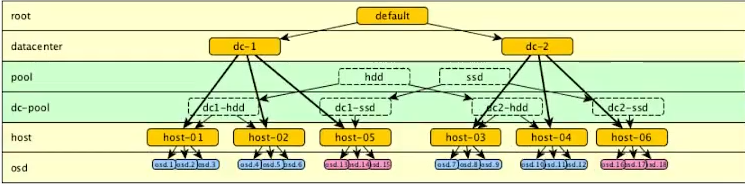
CRUSH 桶类型
对于大规模的安装,可以创建一个特定的层次结构来描述存储基础设施
比如:数据中心—机架—主机—OSD设备
桶是CRUSH层次结构中的容器或分支。设备是osd,是CRUSH层次结构中的叶子。
桶属性
1.桶ID为负数,便于和存储设备区分ID
2.桶名称
3.桶类型
默认的映射定义了几种类型。比如:根root、区域region、数据中心dc、房间、pod、pdu、行、机架、机箱、主机
也可以添加自定义类型
4.算法
当PG副本映射到osd时,ceph用来选择桶内项目的算法。有几种可用的算法:uniform、list、tree、straw2,默认为straw2
自定义故障域与性能域
CRUSH映射是CRUSH算法的中心配置机制,可以通过编辑此映射来影响数据放置和自定义CRUSH算法
创建独立的故障域允许OSD和集群节点在不发生数据丢失的情况下发生故障,集群会进入降级状态下运行,直到问题解决
创建独立的性能域可以减少ceph客户端和应用程序的性能瓶颈
定制CRUSH映射的一个经典用例是针对硬件故障做额外的保护:缺省情况下,CRUSH算法将复制的对象放在不同主机的OSD上
自定义OSD CRUSH设置
CRUSH映射包含了存储设备的列表,对每个存储设备,可获取的信息包括:
1.存储设备ID
2.存储设备
3.存储设备的权重,通常以TB为单位,比如4TB的权重约为4.0。以确保对象的均匀分布
ceph OSD crush reweight可以设置OSD的权重,但不推荐修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| class反应了设备的类型,比如hdd,ssd,NVMe ssd等
查看当前crush层级
ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 0.52734 root default
-5 0.17578 host cephadm-1
4 hdd 0.05859 osd.4
6 hdd 0.05859 osd.6
8 hdd 0.05859 osd.8
-7 0.17578 host cephadm-2
3 hdd 0.05859 osd.3
5 hdd 0.05859 osd.5
7 hdd 0.05859 osd.7
-3 0.17578 host cephadm-3
0 hdd 0.05859 osd.0
1 hdd 0.05859 osd.1
2 hdd 0.05859 osd.2
|
使用CRUSH RULE规则
CRUSH Map包含多个CRUSH Rule(规则集),决定了如何将PG映射到OSD中存储对象副本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| ceph osd crush rule ls
replicated_rule
ceph osd crush rule dump replicated_rule
{
"rule_id": 0,
"rule_name": "replicated_rule",
"type": 1,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
或者
ceph osd getcurshmap -o ./map.bin
crushtool -d ./map.bin -o ./map.txt
cat map.txt
...
rule replicated_rule {
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
|
CRUSH规则的属性
1.rule_name规则的名称,使用ceph osd pool create时,会指定规则的名称
2.rule_id规则的ID,有些命令会使用规则的ID而不是名称
3.min_size如果生成的副本少于这个数,则CRUSH不选择此规则
4.max_size如果生产的副本多于这个数,则CRUSH不选择此规则
5.step take从这个桶开始迭代,这里是default,一般不会设定为根桶
6.step chooseleaf以这个桶作为最小单位来划分,这里是host主机桶
(1)如果三副本的池,那就需要3个主机桶,这三个主机桶中分别找三个OSD
(2)如果firstn后是0,则池中有多少副本就选多少桶
(3)如果firstn大于0且小于副本数,那就需要额外的步骤来定义规则,来存放多出来的副本
使用CRUSH MAP映射
使用ceph命令自定义CRUSH MAP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 创建桶的命令格式:
ceph osd crush add-bucket <name> <type>
name名字
type桶类型
创建三个桶,一个dc类型的,两个rack类型的
ceph osd crush add-bucket DC1 datacenter
ceph osd crush add-bucket rackA1 rack
ceph osd crush add-bucket rackB1 rack
重新组织树的命令格式:
ceph osd crush move <name> <type>=<上级桶的名称>
两个机架桶挂载到数据中心桶上,并将数据中心桶挂载到default根桶上
ceph osd crush move rackA1 datacenter=DC1
ceph osd crush move rackB1 datacenter=DC1
ceph osd crush move DC1 root=default
|
设置OSD位置
自定义了层次结构之后,就要加入OSD作为leaf来存放数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| OSD的位置是一个字符串,记录了从根开始完整的路径
和linux的绝对路径差不多
root=default datacenter=DC1 rack=rackA1
当Ceph启动时,使用Ceph-crush-location utility自动验证每个OSD
是否在正确的crush位置,如果不在映射中的预期位置,会自动移动到默认的
root=default host=hostname下
命令行配置crush_location参数(推荐)
ceph orch daemon reconfig osd.0 --crush-location 'root=default,datacenter=DC1'
或者
ceph osd crush set osd.0 1.0 root=default datacenter=DC1 rack=rackA1 host=<主机名>
/etc/ceph/ceph.conf配置文件中,配置crush_location参数(不推荐)
[osd.0]
crush_location = root=default datacenter=DC1 rack=rackA1
[osd.1]
crush_location = root=default datacenter=DC1 rack=rackB1
|
给CRUSH MAP添加规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 创建新的CRUSH规则
ceph osd crush rule create-replicated <rule-name> <root> \
<failure-domain-type> [class]
rule-name规则名称
root起始桶
failure-domain-type故障域类型(确保副本分布在不同故障域中)
class要使用的设备的类,可选,如hdd ssd
ceph osd crush rule create-replicated inDC2 DC2 rack
ceph osd crush rule ls
表示
使用新的CRUSH规则
ceph osd pool create mypool 128 128 inDC2
|
PG优化
一般不会做
在集群生命周期中,pg的数量必须随着集群布局的变化而调整。CRUSH尝试确保池中osd之间的对象均匀分布,但是存在pg变得不平衡的情况。
数量或者体积大的对象,都会导致PG对象分布不平衡
红帽建议每个OSD中创建100~200个PG
PG数量计算
对于单池的集群,可以使用以下公式:
1
2
3
| 120个OSD,3副本池,目标每个OSD承载100个PG
(120 OSD × 100 PG/OSD) / 3 副本 = 4000
|
管理OSD MAP
集群OSD映射中包含了每个OSD的地址、状态、池列表和详细信息,以及OSD临近容量限制信息等
每次OSD加入或退出集群时,ceph都会更新OSD映射,OSD退出集群的原因包括OSD故障或者硬件故障
不使用leader,OSD之间互相传播映射,标记他们与OSD map epoch交换的每个消息,当检测到自己落后时,就会进行更新
使用epoch标记与更新OSD信息,与ceph客户端连接时,也会给ceph客户端进行更新增量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| ceph osd dump
ompat_client luminous
require_osd_release quincy
stretch_mode_enabled false
pool 1 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 51 lfor 0/0/23 flags hashpspool stripe_width 0 application rgw
pool 2 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 51 lfor 0/0/23 flags hashpspool stripe_width 0 application rgw
pool 3 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 20 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr
pool 4 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 57 lfor 0/0/54 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.meta' replicated si
min_cze 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 57 lfor 0/0/55 flags hashpspool stripe_width 0 pg_autoscale_bias 4 application rgw
max_osd 9
osd.0 up in weight 1 up_from 12 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.143:6800/2523430589,v1:192.168.10.143:6801/2523430589] [v2:192.168.10.143:6802/2523430589,v1:192.168.10.143:6803/2523430589] exists,up f6177fb9-920a-4fe3-a739-4d607bd567de
osd.1 up in weight 1 up_from 14 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.143:6808/1943165126,v1:192.168.10.143:6809/1943165126] [v2:192.168.10.143:6810/1943165126,v1:192.168.10.143:6811/1943165126] exists,up aa74b56a-0307-458b-8016-d98563f08798
osd.2 up in weight 1 up_from 16 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.143:6816/1907316690,v1:192.168.10.143:6817/1907316690] [v2:192.168.10.143:6818/1907316690,v1:192.168.10.143:6819/1907316690] exists,up 20144dcf-136a-49e6-ba1b-b6e10975024b
osd.3 up in weight 1 up_from 37 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.142:6800/3086155865,v1:192.168.10.142:6801/3086155865] [v2:192.168.10.142:6802/3086155865,v1:192.168.10.142:6803/3086155865] exists,up af6bed47-8287-43a8-a7ba-8e927bda1e58
osd.4 up in weight 1 up_from 37 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.141:6800/352319272,v1:192.168.10.141:6801/352319272] [v2:192.168.10.141:6802/352319272,v1:192.168.10.141:6803/352319272] exists,up 155a4723-e4ce-4e5a-9791-85f8d84a3a3c
osd.5 up in weight 1 up_from 40 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.142:6808/1669659193,v1:192.168.10.142:6809/1669659193] [v2:192.168.10.142:6810/1669659193,v1:192.168.10.142:6811/1669659193] exists,up 0b74231f-8c31-40c7-92fe-51b995a82446
osd.6 up in weight 1 up_from 40 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.141:6808/2374217427,v1:192.168.10.141:6809/2374217427] [v2:192.168.10.141:6810/2374217427,v1:192.168.10.141:6811/2374217427] exists,up cd382a85-1b85-406c-a792-8a2bf1b29b3a
osd.7 up in weight 1 up_from 43 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.142:6816/2034759112,v1:192.168.10.142:6817/2034759112] [v2:192.168.10.142:6818/2034759112,v1:192.168.10.142:6819/2034759112] exists,up 7417a159-b3a0-4995-b39b-4fd0648c33ee
osd.8 up in weight 1 up_from 43 up_thru 116 down_at 0 last_clean_interval [0,0) [v2:192.168.10.141:6816/3067034779,v1:192.168.10.141:6817/3067034779] [v2:192.168.10.141:6818/3067034779,v1:192.168.10.141:6819/3067034779] exists,up 1cfdad67-9201-462f-9fb4-3e0665d4a059
...
|
