本文默认读者是一个helm糕手,会略过一些基础的概念,仅对关键部分做解释
Milvus是一个向量数据库,但是和之前用过的Chorma和FAISS相比,更加倾向于是一个功能完整的分布式数据库
维度 FAISS Chroma Milvus
定位 高性能向量搜索库
轻量级向量数据库
云原生分布式向量数据库
核心特点 极致检索速度、支持GPU加速
极简API、与LangChain等AI框架无缝集成
完整的数据管理能力、支持分布式、混合检索
架构/部署 本地嵌入式库 ,无服务端
本地或Docker部署,嵌入式优先
分布式、云原生,可部署在K8s上或使用云服务
数据规模 十亿级 (通过GPU/多卡)百万级 百亿/千亿级
索引与功能 提供多种索引算法(IVF, HNSW, PQ),但无数据持久化、无CRUD ,只是搜索库
基础索引,支持元数据过滤,但不支持复杂混合检索
支持向量与标量字段的混合检索 、数据分区、多副本、高可用等完整数据库特性
性能指标 极致快 (毫秒级,尤其在GPU上),纯算法层优化较快,但在大规模数据和高并发场景下性能衰减明显
快 (毫秒级,<50ms),且在亿级数据下性能表现稳定 ,高QPS
易用性 较高 ,需自行集成和管理索引文件极高 ,几行Python代码即可运行中等 ,功能丰富,但需要一定的运维知识(尤其是自建)
典型场景 学术研究、对性能有极致要求的特定场景、作为其它数据库的核心引擎
快速原型验证 、个人项目、Jupyter Notebook中的AI实验企业级生产环境 、大规模RAG应用、推荐系统、多模态搜索
Milvus现在也支持单机部署或使用Lite轻量版直接用pip安装,不过我这里肯定是用更高级的方法部署,也就是Helm部署
参考文档:https://milvus.io/docs/zh/overview.md
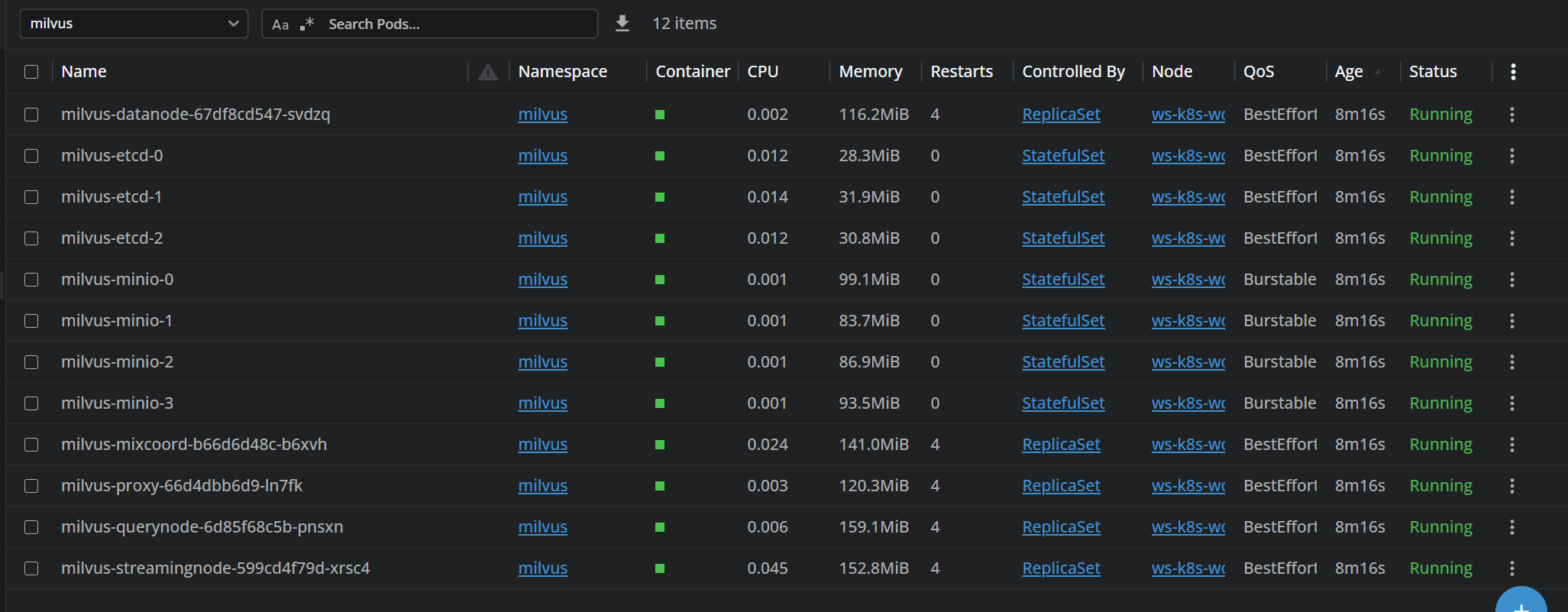
Helm部署 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE standard (default) rancher.io/local-path Delete WaitForFirstConsumer false 5d5h helm repo add zilliztech https://zilliztech.github.io/milvus-helm/ helm repo update helm install my-release zilliztech/milvus \ --set image.all.tag=v2.6.11 \ --set pulsarv3.enabled=false \ --set woodpecker.enabled=true \ --set streaming.enabled=true \ --set indexNode.enabled=false helm search repo zilliztech/milvus --versions NAME CHART VERSION APP VERSION DESCRIPTION zilliztech/milvus 5.0.16 2.6.13 Milvus is an open-source vector database built ... zilliztech/milvus 5.0.15 2.6.12 Milvus is an open-source vector database built ... zilliztech/milvus 5.0.14 2.6.11 Milvus is an open-source vector database built ... ... helm pull zilliztech/milvus --version 5.0.14 --untar cd milvus/上面他关闭和开启的几个模块: pulsarv3 Pulsar (消息队列)因为启用了woodpecker,所以不需要了 woodpecker 啄木鸟 云原生预写日志(WAL)系统,作用是替代外部的消息队列 streaming 流服务 提供流数据的接入、管理和订阅功能,默认使用minio,也可以用公有云服务 indexNode 索引节点,用以加速向量检索,但消耗资源 pulsarv3.enabled=false woodpecker.enabled=true streaming.enabled=true indexNode.enabled=false etcd.persistence.storageClass=standard minio.persistence.storageClass=standard helm upgrade --install milvus . -f ./values.yaml -n milvus --create-namespace
配置Milvus使用OSS 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 mc ls mlivus/milvus-wangsheng-test/ [2026-03-23 22:18:01 CST] 0B test / minio: enabled: false ... externalS3: enabled: true host: "oss-cn-beijing.aliyuncs.com" port: "443" accessKey: "LTAIxxxx" secretKey: "qbfxxxxx" useSSL: true bucketName: "milvus-wangsheng-test" rootPath: "test" useIAM: false cloudProvider: "aliyun" iamEndpoint: "" region: "cn-beijing" useVirtualHost: true helm delete milvus -n milvus kubectl delete pvc --all -n milvus helm upgrade --install milvus . -f ./values.yaml -n milvus --create-namespace
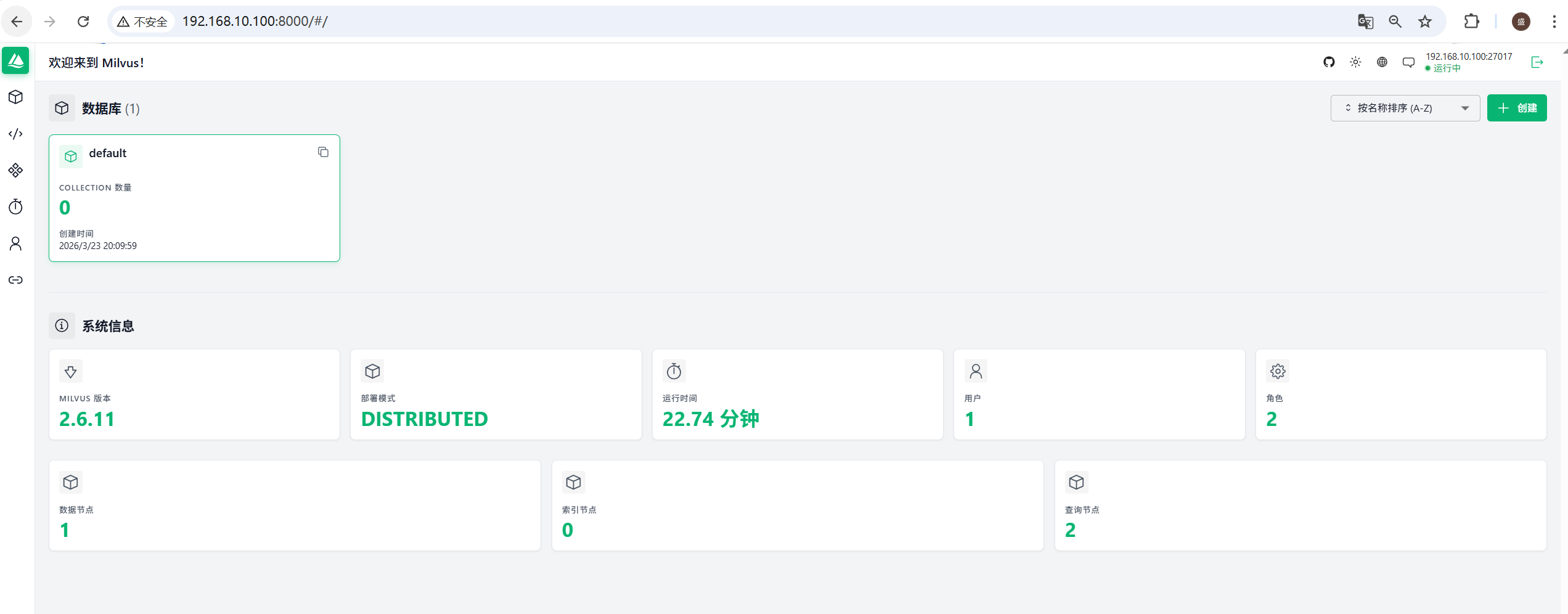
部署Attu可视化看板 Attu 是 Milvus 官方推出的开源图形化管理工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 kubectl -n milvus port-forward --address 0.0.0.0 service/milvus 27017:19530 & kubectl -n milvus port-forward --address 0.0.0.0 svc/milvus 9091:9091 & docker run -d \ --name attu \ -p 8000:3000 \ -e MILVUS_URL=192.168.10.100:27017 \ zilliz/attu:latest
理解Milvus 要使用milvus首先要理解milvus的基本理论知识存储与计算分离 的架构,它把整个系统拆成了四个层级:
**接入层 (Access Layer/Proxy)**:
**协调器 (Coordinators)**:
执行节点 (Worker Nodes):QueryNode (负责搜)、 DataNode (负责写)和 IndexNode (负责建立索引)。**存储层 (Storage)**:
**对象存储 (OSS/MinIO)**:存放真正的向量数据和索引文件(你刚才折腾最久的地方)。
**元数据存储 (Etcd)**:存 Collection 结构、Pod 状态等。
消息队列 (Pulsar/Kafka):这是 Milvus 的 血液 。所有的写入操作都会先变成一条消息进入队列。
实际上的使用流程
定义 Schema :选好维度和距离算法。创建 Collection :定好 shards_num(影响写入吞吐)。插入数据 :批量插入(Batch Insert)效率远高于单条。建立索引 :选好 index_type(影响查询延迟)。Load :设置 replica_number(影响查询并发)。Search :开始你的向量检索。
使用Milvus 在理解流程的基础上,我准备使用我之前用langchain写的一个streamlit的项目,小改一手让他用milvus
是我高估自己了,我是个菜逼,整了半天硬是跑不通,算了算了,这种问题让开发去想吧
测试milvus连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 cd langchain_project_PDF/conda activate langchain pip install -U pymilvus cat > test_milvus.py <<EOF from pymilvus import connections, utility def test_connection(): print("正在尝试连接 Milvus...") try: # 设置一个短的 timeout,防止无限等待 connections.connect( alias="default", host="192.168.10.100", port="27017", timeout=5 ) # 获取服务器版本,这是最轻量的请求 version = utility.get_server_version() print(f"✅ 连接成功!Milvus 版本: {version}") # 列出所有集合名 collections = utility.list_collections() print(f"当前数据库中的集合: {collections}") except Exception as e: print(f"❌ 连接失败: {e}") finally: connections.disconnect("default") if __name__ == "__main__": test_connection() EOF python test_milvus.py 正在尝试连接 Milvus... ✅ 连接成功!Milvus 版本: 2.6.11 当前数据库中的集合: []