一直听说 VM 压缩率比 Prometheus 高 7 倍,手上正好有套 kube-prometheus-stack 跑在 Kind 集群,从零搭一套把告警链路跑通。
单机版部署与接入Prometheus
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
export http_proxy="http://192.168.10.238:7897"
export https_proxy="http://192.168.10.238:7897"
git clone https://github.com/VictoriaMetrics/helm-charts.git
unset http_proxy
unset https_proxy
cd helm-charts/charts/victoria-metrics-single/
helm dependency build
helm upgrade --install vm-single . -f values.yaml -n victoria-metrics --create-namespace
kubectl port-forward --address 0.0.0.0 -n victoria-metrics svc/victoria-metrics-single-server 8428:8428 &
|
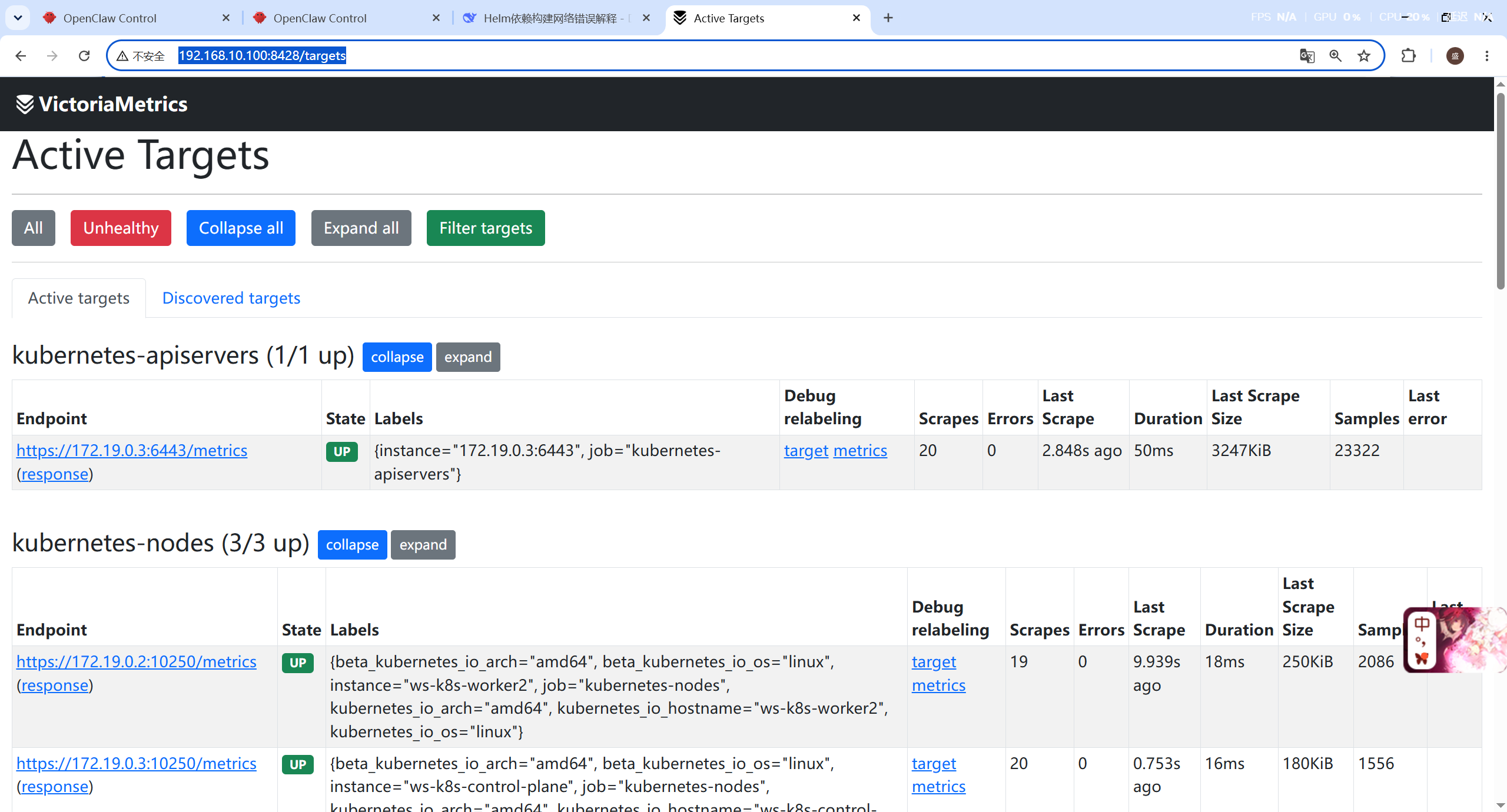
MetricsQL
VM 的查询语言,兼容 PromQL,加了几个好用的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
WITH (
errors = sum(rate(http_requests_total{status=~"5.."})),
total = sum(rate(http_requests_total))
)
errors / total * 100
rate(http_requests_total)
rollup(metric, "max")
rollup(metric, "avg")
keep_last_value(up)
sum by (instance) (rate(node_cpu_seconds_total{mode!="idle"})) | topk(5)
|
| 特性 |
PromQL |
MetricsQL |
| 默认 range |
❌ 必须写[5m] |
✅ 自动 |
| WITH 语法 |
❌ |
✅ |
| rollup |
❌ |
✅ |
| keep_last_value |
❌ |
✅ |
| 管道语法 |
❌ |
✅ |
通过 Promxy 查 VM 时用标准 PromQL API,不会走 MetricsQL。
k8s-stack 集群版部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
helm delete vm-single -n victoria-metrics
cd /root/victoria-metrics/charts/victoria-metrics-k8s-stack/
helm dependency build
helm upgrade --install victoria-metrics-k8s-stack ./ -f values.yaml -n victoria-metrics
kubectl port-forward --address 0.0.0.0 -n victoria-metrics svc/vmselect-victoria-metrics-k8s-stack 8481:8481 &
kubectl port-forward --address 0.0.0.0 -n victoria-metrics svc/vmalert-victoria-metrics-k8s-stack 8080:8080 &
kubectl port-forward --address 0.0.0.0 -n victoria-metrics svc/vmagent-victoria-metrics-k8s-stack 8429:8429 &
|
集群版三组件:vminsert 写入路由,vmstorage 存储,vmselect 查询。可独立扩缩容。
k8s-stack 用 Operator 模式,跟 kube-prometheus-stack 套路一样:
|
kube-prometheus-stack |
victoria-metrics-k8s-stack |
| 添加监控目标 |
ServiceMonitor |
VMServiceScrape |
| 配置告警规则 |
PrometheusRule |
VMRule |
Operator 自动兼容 Prometheus Operator 的 CRD,迁移基本不用改。
告警实战与邮件通知
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
stress --vm 1 --vm-bytes 6500M --timeout 600s
|

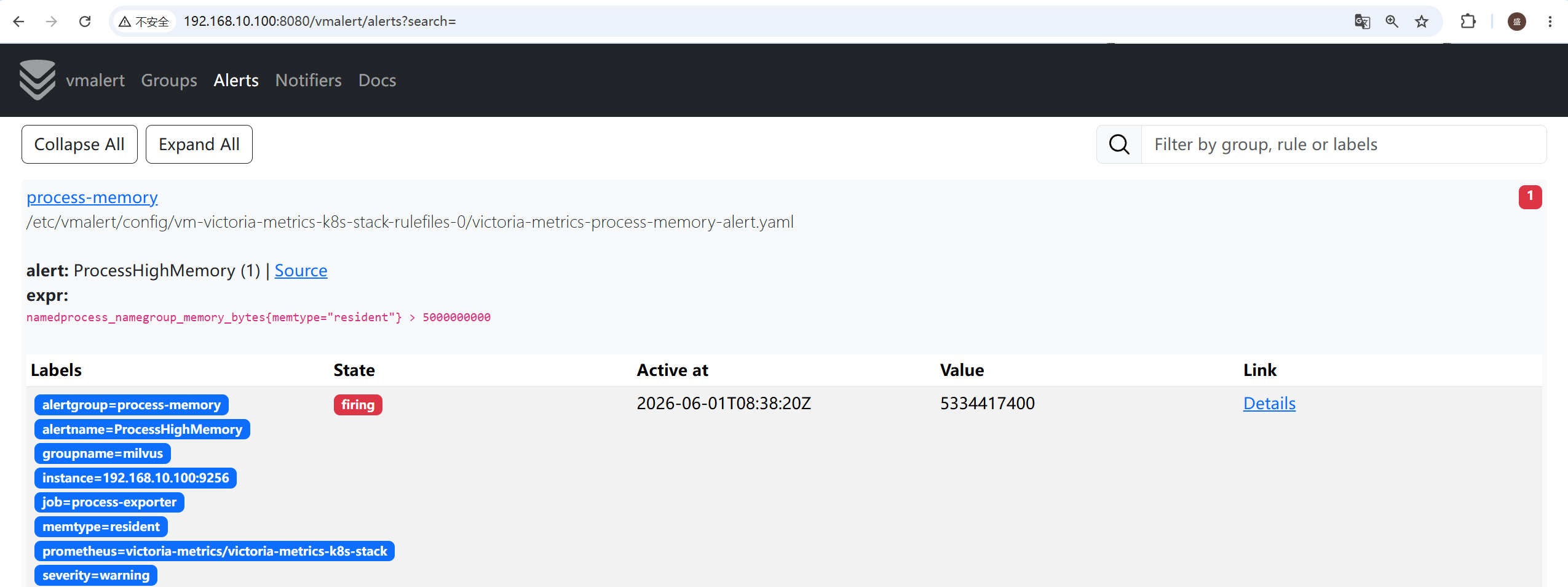
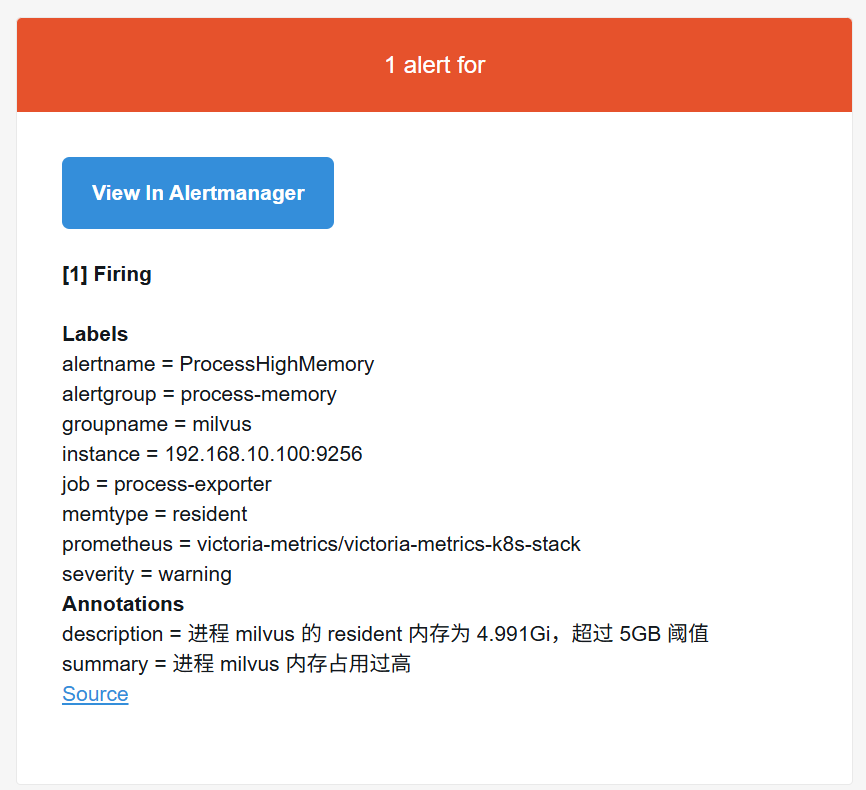
整体链路:采集(vmagent) → 存储(VM) → 查询(MetricsQL) → 告警(vmalert) → 通知(Alertmanager → 邮件)
Helm依赖缺失:helm dependency build 不能省。node-exporter端口冲突:kube-prometheus-stack已占用9100。defaultRules不兼容:Kind环境部分告警规则表达式不匹配。集群版VMUI路径:要带租户ID /select/0/vmui。
环境版本
| 组件 |
版本 |
| kube-prometheus-stack (Helm) |
80.13.2 |
| Prometheus |
v3.9.1 |
| Grafana |
12.3.1 |
| VM k8s-stack (Helm) |
0.81.0 |
| VM App Version |
v1.144.0 |
| process-exporter |
v0.8.1 |
遗留任务
